
GitHub - Ck44liu/modular-reinforcement-learning
GitHub - Ck44liu/modular-reinforcement-learning This letter presents modular reinforcement learning (rl) frameworks for the low level control of a quadrotor, with direct control of yawing motion. This repository implements both monolithic and modular reinforcement learning (rl) frameworks for the low level control of a quadrotor unmanned aerial vehicle. a detailed explanation of these concepts can be found in this video.
 Vs. Hierarchical Reinforcement... | Download Scientific ...")
Modular Reinforcement Learning (left) Vs. Hierarchical Reinforcement... | Download Scientific ...
Modular Reinforcement Learning (left) Vs. Hierarchical Reinforcement... | Download Scientific ... This study addresses the limitations of traditional rl approaches for quadrotor control by decomposing the quadrotor dynamics into translational and yaw subsystems, resulting in more efficient training and enhanced yaw control performance. This paper presents data eficient equivariant reinforcement learning strategies for quadrotor control by leveraging the inherent symmetries of quadrotor dynamics. In this video, we demonstrate a modular reinforcement learning (rl) framework for the low level control of a quadrotor, including direct control of yawing motion. Modular reinforcement learning for a quadrotor uav with decoupled yaw control ieee robotics and automation letters ( if 5.3 ) pub date : 2024 12 04 , doi: 10.1109/lra.2024.3511412.

Adaptive Modular Reinforcement Learning Architecture. | Download Scientific Diagram
Adaptive Modular Reinforcement Learning Architecture. | Download Scientific Diagram In this video, we demonstrate a modular reinforcement learning (rl) framework for the low level control of a quadrotor, including direct control of yawing motion. Modular reinforcement learning for a quadrotor uav with decoupled yaw control ieee robotics and automation letters ( if 5.3 ) pub date : 2024 12 04 , doi: 10.1109/lra.2024.3511412. Particularly, the mod emlp model, combining equivariant learning with a modular architecture, shows superior early stage performance and faster convergence due to parallel learning of translational and yawing motions. To address these issues, we decompose the quadrotor dynamics into translational and yaw subsystems and assign a dedicated modular rl agent to each. this design significantly improves performance, as each rl agent is trained for its specific purpose and integrated in a synergistic way. Quadswarm, with fast forward dynamics propagation decoupled from rendering, is designed to be highly parallelizable such that throughput scales linearly with additional compute. To execute a runner script run the following command: this command will start training four different seeds in parallel on a 4 gpu server. adjust the parameters accordingly to match your hardware setup. to monitor the experiments, go to the experiment folder, and run the following command: tensorboard logdir=./.

Adaptive Modular Reinforcement Learning Architecture. | Download Scientific Diagram
Adaptive Modular Reinforcement Learning Architecture. | Download Scientific Diagram Particularly, the mod emlp model, combining equivariant learning with a modular architecture, shows superior early stage performance and faster convergence due to parallel learning of translational and yawing motions. To address these issues, we decompose the quadrotor dynamics into translational and yaw subsystems and assign a dedicated modular rl agent to each. this design significantly improves performance, as each rl agent is trained for its specific purpose and integrated in a synergistic way. Quadswarm, with fast forward dynamics propagation decoupled from rendering, is designed to be highly parallelizable such that throughput scales linearly with additional compute. To execute a runner script run the following command: this command will start training four different seeds in parallel on a 4 gpu server. adjust the parameters accordingly to match your hardware setup. to monitor the experiments, go to the experiment folder, and run the following command: tensorboard logdir=./.
 A MODULAR REINFORCEMENT LEARNING METHOD FOR … · A MODULAR REINFORCEMENT LEARNING METHOD ...")
(PDF) A MODULAR REINFORCEMENT LEARNING METHOD FOR … · A MODULAR REINFORCEMENT LEARNING METHOD ...
(PDF) A MODULAR REINFORCEMENT LEARNING METHOD FOR … · A MODULAR REINFORCEMENT LEARNING METHOD ... Quadswarm, with fast forward dynamics propagation decoupled from rendering, is designed to be highly parallelizable such that throughput scales linearly with additional compute. To execute a runner script run the following command: this command will start training four different seeds in parallel on a 4 gpu server. adjust the parameters accordingly to match your hardware setup. to monitor the experiments, go to the experiment folder, and run the following command: tensorboard logdir=./.

Modular Reinforcement Learning For A Quadrotor UAV
Modular Reinforcement Learning For A Quadrotor UAV
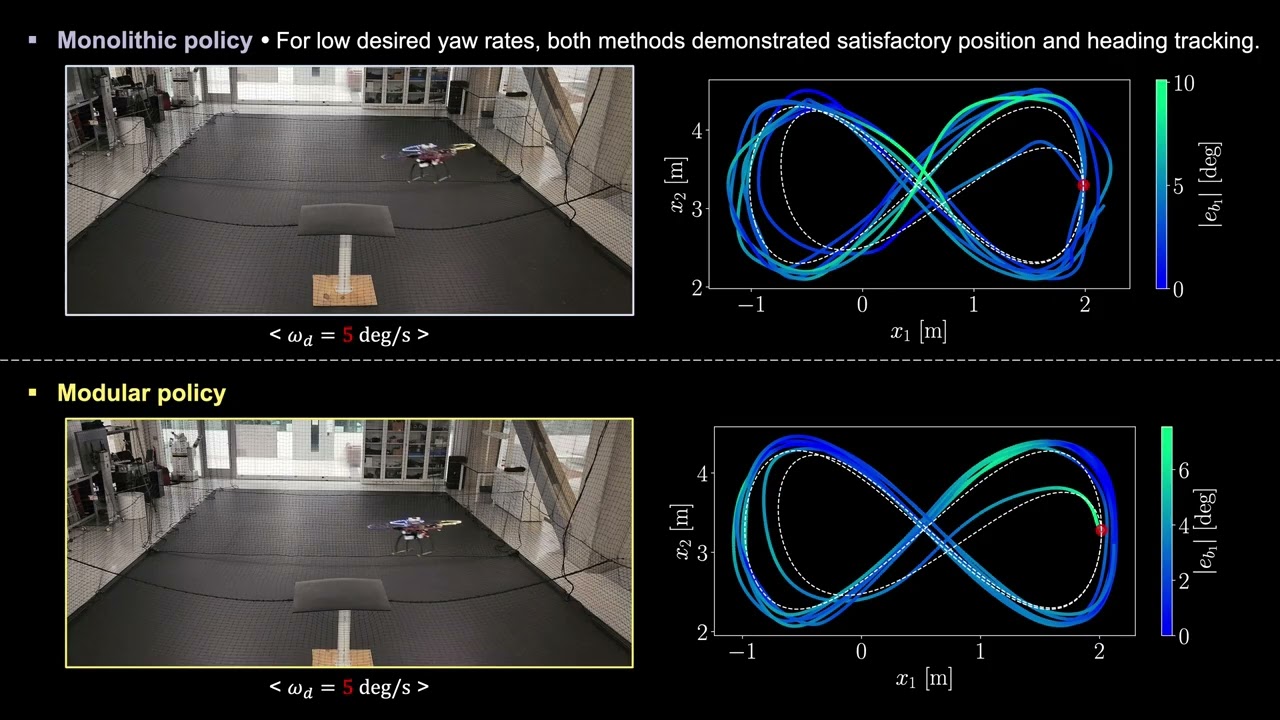
Modular Reinforcement Learning for a Quadrotor with Decoupled Yaw
Modular Reinforcement Learning for a Quadrotor with Decoupled Yaw
Related image with modular reinforcement learning for a quadrotor with decoupled yaw

 Vs. Hierarchical Reinforcement... | Download Scientific ...")


 A MODULAR REINFORCEMENT LEARNING METHOD FOR … · A MODULAR REINFORCEMENT LEARNING METHOD ...")






Related image with modular reinforcement learning for a quadrotor with decoupled yaw



")
About "Modular Reinforcement Learning For A Quadrotor With Decoupled Yaw"
Comments are closed.