
OpenAI Research
OpenAI Research We’re introducing a neural network called clip which efficiently learns visual concepts from natural language supervision. clip can be applied to any visual classification benchmark by simply providing the names of the visual categories to be recognized, similar to the “zero shot” capabilities of gpt‑2 and gpt‑3. We study the performance of this approach by benchmarking on over 30 different existing computer vision datasets, spanning tasks such as ocr, action recognition in videos, geo localization, and.

CLIP: Connecting Text And Images | OpenAI
CLIP: Connecting Text And Images | OpenAI After watching your video and you mentioned the code is on github, i wanted to give it a challenge. i was surprised at how much better it was at those adversarial imagenet results. Openai approaches such as the contrastive language image pre training (clip)¹ aim at reducing this complexity thus allowing developers to focus on practical cases. clip is a neural network trained on a large set (400m) of image and text pairs. Created by the geniuses at openai, clip bridges the gap between images and text by learning from both at the same time. it’s like giving a computer the ability to read and see. Openai's clip (contrastive language image pretraining) represents a groundbreaking advancement in the convergence of image and text processing. by utilizing a dual encoder architecture, clip effectively bridges the gap between visual data and textual information, enabling powerful zero shot learning capabilities.

OpenAI-Clip - Qualcomm AI Hub
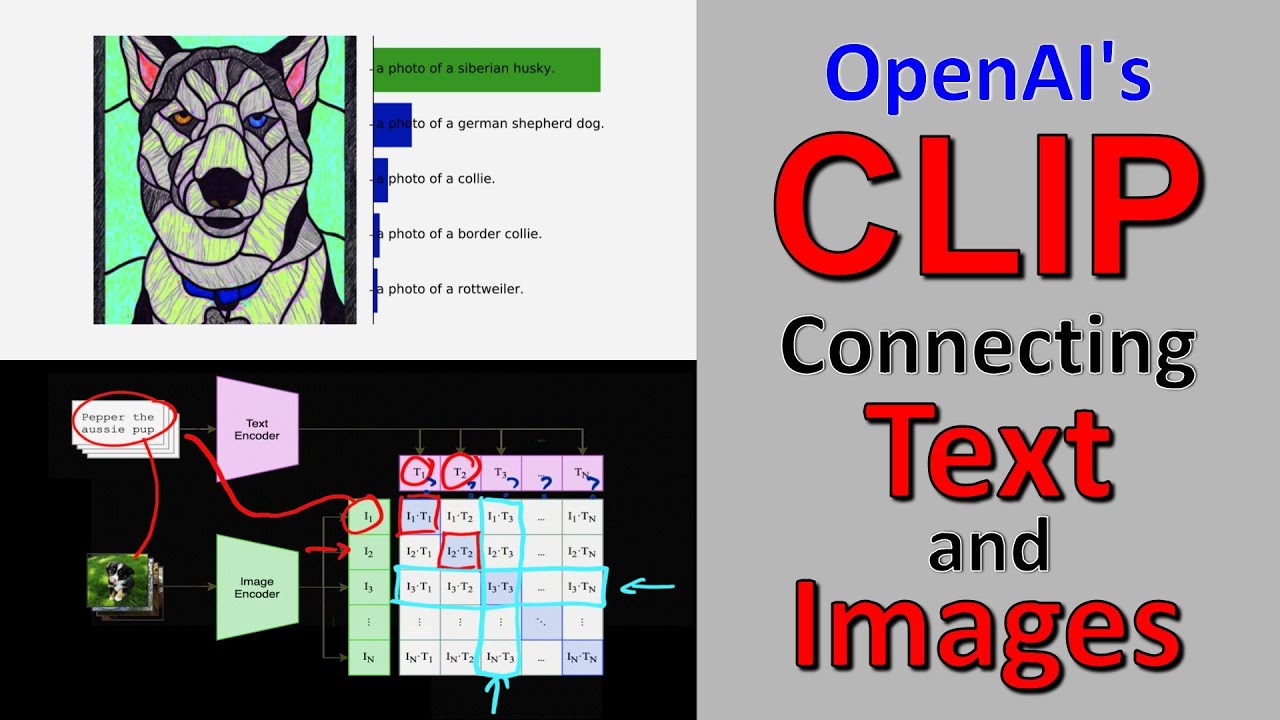
OpenAI-Clip - Qualcomm AI Hub Created by the geniuses at openai, clip bridges the gap between images and text by learning from both at the same time. it’s like giving a computer the ability to read and see. Openai's clip (contrastive language image pretraining) represents a groundbreaking advancement in the convergence of image and text processing. by utilizing a dual encoder architecture, clip effectively bridges the gap between visual data and textual information, enabling powerful zero shot learning capabilities. With these, we can create n x n possible (image, text) pairings across a batch. now, the task is to predict the n real pairs in the batch. to do so, clip learns a multi modal embedding space by jointly training an image encoder and text encoder (see figure 1). In this article, we will explore the openai clip model, which is a powerful multimodal model that connects text and images. it has been pre trained on a large dataset of image text pairs and can be used for a variety of computer vision tasks, including object recognition, image classification, and more. By understanding these concepts, viewers gain a solid grasp of *modern machine learning practices* aimed at improving **image recognition** and **language processing**. whether you're a beginner or an expert, this content greatly enriches your knowledge of ai technologies and their applications. We’re introducing a neural network called clip which efficiently learns visual concepts from natural language supervision.

Free Video: OpenAI CLIP - Connecting Text And Images - Paper Explained From Aleksa Gordić - The ...
Free Video: OpenAI CLIP - Connecting Text And Images - Paper Explained From Aleksa Gordić - The ... With these, we can create n x n possible (image, text) pairings across a batch. now, the task is to predict the n real pairs in the batch. to do so, clip learns a multi modal embedding space by jointly training an image encoder and text encoder (see figure 1). In this article, we will explore the openai clip model, which is a powerful multimodal model that connects text and images. it has been pre trained on a large dataset of image text pairs and can be used for a variety of computer vision tasks, including object recognition, image classification, and more. By understanding these concepts, viewers gain a solid grasp of *modern machine learning practices* aimed at improving **image recognition** and **language processing**. whether you're a beginner or an expert, this content greatly enriches your knowledge of ai technologies and their applications. We’re introducing a neural network called clip which efficiently learns visual concepts from natural language supervision.

Free Video: OpenAI CLIP- Connecting Text And Images From Yannic Kilcher | Class Central
Free Video: OpenAI CLIP- Connecting Text And Images From Yannic Kilcher | Class Central By understanding these concepts, viewers gain a solid grasp of *modern machine learning practices* aimed at improving **image recognition** and **language processing**. whether you're a beginner or an expert, this content greatly enriches your knowledge of ai technologies and their applications. We’re introducing a neural network called clip which efficiently learns visual concepts from natural language supervision.

Embedding Sequence Of Images Into CLIP · Issue #307 · Openai/CLIP · GitHub
Embedding Sequence Of Images Into CLIP · Issue #307 · Openai/CLIP · GitHub
OpenAI CLIP: ConnectingText and Images (Paper Explained)
OpenAI CLIP: ConnectingText and Images (Paper Explained)
Related image with openai clip connectingtext and images paper explained






, Predict The Most ...")





Related image with openai clip connectingtext and images paper explained
")



About "Openai Clip Connectingtext And Images Paper Explained"
Comments are closed.